
El modelado de datos: la integración de datos en la industria 4.0
El modelado de datos es esencial para todos los entornos industriales, según el autor, que realiza una descripción general de su funcionamiento y destaca su aportación a la mejora de las funcionalidades de la información en la industria 4.0, pero advierte de que hace falta disponer de una estrategia adecuada para sacar el máximo partido de esta herramienta
 Antonio Mas Vicent
Antonio Mas Vicent
8 de febrero de 2022
|
Compartir:


La transformación digital está proporcionando a las organizaciones industriales una cantidad enorme de visibilidad y conocimientos predictivos de sus operaciones. Todos los días, fábricas y otros entornos industriales están adoptando tecnologías nuevas e inteligentes que entregan grandes cantidades de datos que pueden ser utilizados para optimizar la producción, predecir errores o fallos y mejorar la calidad del producto final. Sin embargo, conectar estas máquinas a plataformas de almacenamiento de datos o sistemas empresariales no siempre es perfecto. Requiere un estandarizado enfoque para definir y categorizar los datos, de forma que todos en la organización tengan una única fuente y puedan así tomar decisiones más rápidas e informadas.
En este artículo vamos a tratar de proporcionar una descripción general completa del modelado de datos y las soluciones DataOps y por qué es esencial para todos los entornos industriales, sin importar dónde se encuentre la organización a lo largo de su viaje digital, cómo este nuevo “approach” a la integración de datos en entornos 4.0 mejora las funcionalidades, reduce errores, contextualiza los datos y los prepara para una verdadera integración global. Trataremos de dar una visión de cómo funciona el modelado de datos, cómo funciona con estándares existentes (como ISA-95) y consejos sobre cómo establecer una estrategia de modelo de datos.
¿Qué es un modelo de datos?
Un modelo de datos es un conjunto de datos y las conexiones existentes entre ellos, de forma que su almacenamiento, actualización, aprovechamiento o acceso sea más sencillo y eficaz por parte de todos los agentes implicados en la organización. Es pues una pieza fundamental a la hora de reunir a todos los integrantes de una empresa que tratarán con los datos, ya que consolida la información hacia casos de uso específicos, como por ejemplo monitorización y supervisión de equipos y procesos, mantenimiento predictivo, trazabilidad, productividad, costes o simplemente sincronizar la información entre diferentes sistemas.
Dicha información puede tener diferentes atributos que definan los datos. En función de la utilidad o de la experiencia del usuario, los modelos de datos reciben diferentes nombres. Sin duda, el modelo referencia que ha sido usado durante años es ISA-95, aunque hoy en día también podemos hablar de otros como MTConnect y OPC UA. Éstos definen tanto la nomenclatura como la representación de los datos o la estructura del modelo. Del mismo modo, también hay muchos modelos de datos propios de marcas o equipos y, por tanto, sin seguir un estándar. Incluso podemos hablar de modelos de datos propios de departamentos como IT o aplicaciones cloud. Como vemos, la diversidad de modelos de datos es enorme y, en la práctica, sigue habiendo poca estandarización.
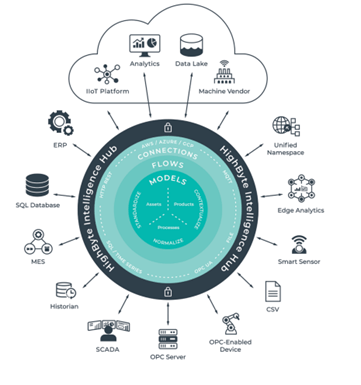
¿Por qué es importante el modelado de datos?
El modelado de datos es importante, sobre todo, en un entorno de industria 4.0. En este artículo vamos a tratar de dar un paso más y explicar por qué es necesaria esa capa de abstracción para el modelado de datos en el camino de conseguir una verdadera infraestructura capaz de escalar. Veamos detenidamente cada aspecto.
a) Un único entorno
Una capa de abstracción dedicada (la llamaremos la capa DataOps) es esencial porque no todas las aplicaciones se ajustan a un solo estándar. Los estándares de la industria existen, pero son finitos. Como tal, los proveedores continúan creando sus propios esquemas para modelar información rica en el contexto de su aplicación. Afortunadamente, los proveedores suelen proporcionar algún nivel de API para enviar y extraer datos de la aplicación en el formato esperado que luego puede aprovechar una capa de modelado de datos dedicada.
Al orquestar estas integraciones dentro de una capa dedicada, podemos comenzar a generar un modelo de datos genérico, de modo que un usuario pueda trabajar en un solo entorno para modelar cualquier cantidad de cosas. Luego, esa capa se convierte en responsable de transformar los datos en los esquemas de modelado de datos específicos para todas las aplicaciones de consumo. Esto es un cambio de juego para los usuarios que necesitan recopilar, fusionar, transformar y compartir información con muchas aplicaciones que se encuentran en las instalaciones y en la nube. Los usuarios pueden crear o implementar nuevas aplicaciones a lo largo del tiempo y aprovechar el trabajo anterior. Cuando el modelado de datos se administra en una ubicación centralizada, los usuarios pueden agregar, eliminar y editar parámetros para aplicaciones conectadas sin romper las integraciones existentes.
b) Visibilidad y flexibilidad
Un solo entorno proporciona visibilidad. A menudo hablamos con el área OT de clientes que saben que tienen hardware y software en planta que producen y recopilan datos sin procesar, pero no saben quién se conecta a ellos y qué datos se comparten. Una ubicación centralizada permite a OT ver fácilmente dónde y cómo fluyen los datos dentro y fuera de la planta. Saben quién produce los datos sin procesar, quién consume la información y cómo los cambios en la capa de DataOps afectarán al resto de la empresa. Una capa dedicada agrega resistencia y flexibilidad al vasto ecosistema de tecnología que se encuentra en la mayoría de las instalaciones de fabricación.
c) Preparación de datos en un solo paso
Una ubicación centralizada también reduce la redundancia en la preparación de datos y disminuye el tiempo de integración del sistema. La información se puede propagar automáticamente a la aplicación de cualquier proveedor sin tocar cada aplicación individualmente. Modelar datos en muchas aplicaciones diferentes lleva mucho tiempo en lugar de modelar datos una sola vez.
d) Conectividad pasiva
Una capa de DataOps proporciona conectividad pasiva, lo que significa que los usuarios no necesitarán programar tiempo de inactividad ni volver a cablear integraciones para establecer comunicación con la solución. Una solución Industrial DataOps puede conectarse pasivamente, hacer conexiones a fuentes de datos existentes, extraer datos, transformarlos, agregarles contexto y luego enviar información modelada en tiempo real a las aplicaciones en ejecución utilizando sus respectivas API.
e) Calidad y precisión de los datos
La capa DataOps transforma los datos sin procesar antes de ponerlos a disposición de todas las aplicaciones consumidoras, por lo que hay menos posibilidades de que se cometan errores en sentido ascendente, como adjuntar las unidades de medida incorrectas a un punto de datos. DataOps reduce la oportunidad de error humano al proporcionar una ubicación central para administrar conversiones y transformaciones. Si hay un error, se detecta rápida y fácilmente sin solucionar los problemas de cada aplicación o sin extraer el código personalizado.
Para los datos que incluyen características de tiempo, la capa DataOps ayuda a garantizar que las marcas de tiempo sean consistentes y precisas en todas las aplicaciones. Cuando las aplicaciones pueden recopilar datos de forma directa e independiente, pueden recopilar diferentes muestras de tiempo dependiendo de la velocidad de cambio de los datos subyacentes. En cambio, al usar una capa de DataOps, los usuarios se aseguran de que todas las aplicaciones reciban la misma muestra de tiempo y estén sincronizadas entre sí, hasta una resolución de milisegundos.
f) Seguridad
Por último, cuando las empresas industriales gestionan el modelado y la integración de datos en una solución de DataOps dedicada, refuerzan su estrategia de defensa en profundidad. El entorno de modelado permite que solo las personas autorizadas determinen qué aplicaciones deben recibir datos y exactamente qué datos deben recibir. Las aplicaciones de consumo ya no tienen acceso ilimitado a las fuentes de datos sin procesar. La solución DataOps abstrae esta conexión directa. Y en lugar de enterrar las integraciones en un código personalizado, son visibles para los usuarios autorizados y ayudan a proteger la infraestructura potencialmente crítica.
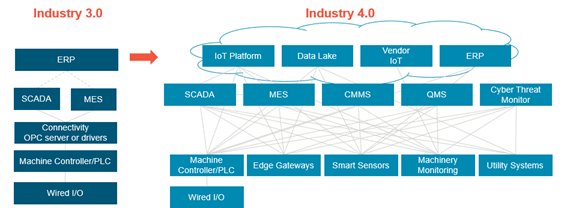
El modelado de datos en cuatro etapas
A estas alturas, nadie duda de la necesidad de disponer de datos que nos posibiliten mayor flexibilidad en las operaciones y una mejora en la eficiencia de nuestros procesos. Pero no debemos caer en el error, muy común por cierto, de pensar que esa necesidad de disponer de datos se resuelve simplemente con capturarlos allá donde se encuentren y, a través de la ciencia de datos, obtener las mejoras que buscamos. Ojalá fuese así de fácil, pero no lo es. Es aquí donde aparece en juego el DataOps, que posibilita la “orquestación” de personas, procesos y tecnología para disponer, de manera segura, de datos fiables, listos para usar y contextualizados, en todos los sistemas y por todas las personas que los necesiten.
Los DataOps son pues necesarios en entornos industriales donde los datos deban ser agregados desde equipos de planta y utilizados por capas superiores de negocio. Pero este recorrido del dato debe realizarse siguiendo un proceso que consta de cuatro etapas.
–Etapa Uno: Acceso a los datos
El acceso a los datos requiere la vinculación de API a través de protocolos abiertos para recopilar valores discretos que podrían informar sobre cómo funcionan los distintos equipos. Un ejemplo puede incluir puntos de datos de consumo de energía, temperatura o presión. En esta etapa, la estructura de los datos son datos de etiquetas y, por lo general, los datos se transportan a la nube o a una base de datos. Por lo general, el equipo de tecnología operativa (OT) entregará los datos al equipo de TI para almacenar los datos sin más.
-Etapa Dos: Contextualización
Una vez que hayamos recopilado y definido los datos, podemos comenzar a crear modelos que incluyan más descriptores, como la ubicación y función de los activos. Comenzamos a normalizar valores con unidades de medida comunes para una operación en particular. Y la estructura de datos en esta etapa es simple. El equipo, que ahora involucra al equipo de OT que envía datos a TI, así como a los ingenieros de datos, estructura la información en un formato básico más identificable.
La etapa de contextualización de datos proporciona puntos de datos contextualizados y estandarizados al equipo de operaciones, lo que les permite comparar puntos de datos similares. El equipo de OT se beneficia al tener información analítica que puede utilizar para tomar decisiones operativas más informadas.
–Etapa Tres: Visibilidad en Planta
Para una visibilidad en planta, necesitamos modelos lógicos estándar de información sobre celdas de trabajo, activos y líneas. La herramienta de habilitación aquí es el Unified Namespace (UNS). Un UNS es una estructura consolidada y abstracta mediante la cual todas las aplicaciones comerciales pueden consumir datos industriales en tiempo real de manera coherente. Un UNS permite combinar múltiples valores en un único modelo lógico estructurado que los usuarios pueden entender y utilizar en todo la planta, para tomar decisiones en tiempo real.
La etapa de visibilidad de planta se centra en proporcionar cargas útiles de información a los usuarios fuera de las operaciones. Estos datos se utilizan normalmente para mejorar la calidad, la investigación y el desarrollo, el mantenimiento de activos, el cumplimiento, la cadena de suministro y más.
-Etapa Cuatro: Visibilidad en Negocio
DataOps para toda la empresa/negocio es similar a la etapa específica de planta en términos de sofisticación de datos, pero ahora puede extender los beneficios a toda la empresa. En la etapa de visibilidad empresarial, sincroniza las estructuras de datos en varios sitios y sistemas dispares. Es posible que tengamos un UNS para toda la empresa y movamos datos de la nube a la periferia. Es decir, está impulsando la analítica desde el nivel empresarial hasta la planta de producción. Aquí es donde la visibilidad de un extremo a otro se convierte en una realidad. Podemos realizar comparaciones de sitio a sitio sin tener que extraer y reemplazar los sistemas existentes. Esta etapa a menudo requiere una colaboración mucho más sólida entre los equipos de OT, TI y transformación digital. Los arquitectos de información empresarial también pueden participar en el proceso de modelado de datos.
La etapa de visibilidad empresarial proporciona el valor más amplio a las empresas, lo que les permite agregar información en todos los sitios con paneles, métricas y análisis comunes. También les permite implementar una sofisticada toma de decisiones basada en datos y automatización de Cloud a Edge.
Toni Mas es CEO de Mas Ingenieros

